FIX tutorial in Java with QuickFIX/j simple example
FIX and Java
| FIX tutorial in Java with QuickFIX/j simple example | QuickFix Java example sending and receiving FIX messages | Finding your way around the FIX specification |
If you like to work on trading applications, you need to know the FIX protocol and a FIX engine like QuickFIX/J.
Q. What is FIX Protocol?
A. FIX stands for Financial Information eXchange, which is an open protocol intended to streamline electronic communications in the financial securities industry. Most of the exchanges use this standard for communication like sending Order, Executions, MarketData, etc. There are many versions of the specifications like 4.2, 4.4, etc. Have a look at https://fixspec.com/FIX44.
Let's have a look at QuickFIX/J and Java example for sending and recieving FIX messages.
Step 1: Required dependency JAR files
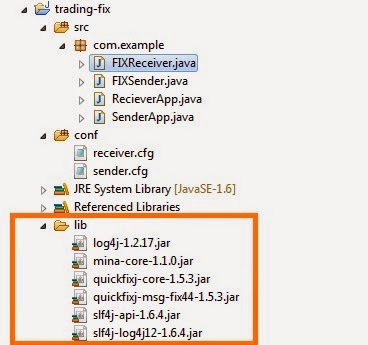
Step 2: The quickfixj-msg-fix44-1.5.3.jar contains the data dictionary for FIX4.4 with domain objects like and XML "NewSingleOrder". Extract FIX44.xml and copy it to c:\\temp.
Step 3: Define the configuration for the receiver or message acceptor. receiver.cfg file in /conf. Needs to be in the classpath.
[DEFAULT] ConnectionType=acceptor SocketAcceptPort=5001 SocketReuseAddress=Y StartTime=00:00:00 EndTime=00:00:00 FileLogPath=log FileStorePath=c:\\temp [SESSION] BeginString=FIX.4.4 SenderCompID=FixServer TargetCompID=CLIENT1 DataDictionary=c:\\temp\\FIX44.xml
Step 4: Define the FIXReceiver class. It extends MessageCracker implements Application. Relevant method gets invoked in this event driven architecture used in MINA.
package com.example;
import quickfix.Application;
import quickfix.DoNotSend;
import quickfix.FieldNotFound;
import quickfix.IncorrectDataFormat;
import quickfix.IncorrectTagValue;
import quickfix.Message;
import quickfix.RejectLogon;
import quickfix.SessionID;
import quickfix.UnsupportedMessageType;
import quickfix.fix44.MessageCracker;
import quickfix.fix44.NewOrderSingle;
public class FIXReceiver extends MessageCracker implements Application {
@Override
public void onMessage(NewOrderSingle order, SessionID sessionID) {
System.out.println("Receiver onMessage.. " + order);
}
@Override
public void fromAdmin(Message arg0, SessionID arg1) throws FieldNotFound, IncorrectDataFormat,
IncorrectTagValue, RejectLogon {
}
@Override
public void fromApp(Message arg0, SessionID arg1) throws FieldNotFound, IncorrectDataFormat,
IncorrectTagValue, UnsupportedMessageType {
System.out.println("Receiver fromApp.. " + arg0);
crack(arg0, arg1); // calls onMessage(..,..)
}
@Override
public void onCreate(SessionID arg0) {
System.out.println("Receiver onCreate.. " + arg0);
}
@Override
public void onLogon(SessionID arg0) {
System.out.println("Receiver onLogon.." + arg0);
}
@Override
public void onLogout(SessionID arg0) {}
@Override
public void toAdmin(Message arg0, SessionID arg1) {}
@Override
public void toApp(Message arg0, SessionID arg1) throws DoNotSend {}
}
Step 5: The server socket code to receive messages. ReceiverApp.Java
package com.example;
import java.util.Scanner;
import quickfix.Application;
import quickfix.ConfigError;
import quickfix.DefaultMessageFactory;
import quickfix.FileStoreFactory;
import quickfix.ScreenLogFactory;
import quickfix.SessionSettings;
import quickfix.SocketAcceptor;
public class RecieverApp {
public static void main(String[] args) throws ConfigError {
SessionSettings settings = new SessionSettings("receiver.cfg");
Application myApp = new FIXReceiver();
FileStoreFactory fileStoreFactory = new FileStoreFactory(settings);
ScreenLogFactory screenLogFactory = new ScreenLogFactory(settings);
DefaultMessageFactory msgFactory = new DefaultMessageFactory();
SocketAcceptor acceptor = new SocketAcceptor(myApp, fileStoreFactory,
settings, screenLogFactory, msgFactory);
acceptor.start();
Scanner reader = new Scanner(System.in);
System.out.println("press <enter> to quit");
//get user input for a
reader.nextLine();
acceptor.stop();
}
}
Step 5: The sender or initiator configuration file sender.cfg.
[DEFAULT] ConnectionType=initiator HeartBtInt=30 ReconnectInterval=0 FileStorePath=c:\\temp FileLogPath=log StartTime=00:00:00 EndTime=00:00:00 UseDataDictionary=N SocketConnectHost=localhost ContinueInitializationOnError=Y [SESSION] BeginString=FIX.4.4 SenderCompID=CLIENT1 TargetCompID=FixServer SocketConnectPort=5001
Step 6: Define the FixSender class that implements Application. Relevant method gets invoked in this event driven architecture used in MINA.
package com.example;
import quickfix.Application;
import quickfix.DoNotSend;
import quickfix.FieldNotFound;
import quickfix.IncorrectDataFormat;
import quickfix.IncorrectTagValue;
import quickfix.Message;
import quickfix.RejectLogon;
import quickfix.SessionID;
import quickfix.UnsupportedMessageType;
public class FIXSender implements Application {
@Override
public void fromAdmin(Message arg0, SessionID arg1) throws FieldNotFound, IncorrectDataFormat,
IncorrectTagValue, RejectLogon {
}
@Override
public void fromApp(Message arg0, SessionID arg1) throws FieldNotFound, IncorrectDataFormat,
IncorrectTagValue, UnsupportedMessageType { }
@Override
public void onCreate(SessionID arg0) {}
@Override
public void onLogon(SessionID arg0) {}
@Override
public void onLogout(SessionID arg0) {}
@Override
public void toAdmin(Message arg0, SessionID arg1) {}
@Override
public void toApp(Message msg, SessionID sessionId) throws DoNotSend {
System.out.println("Sender toApp: " + msg.toString());
}
}
Step 7: The client socket initiator to send FIX messages. SenderApp.java.
package com.example;
import java.util.Date;
import quickfix.Application;
import quickfix.ConfigError;
import quickfix.DefaultMessageFactory;
import quickfix.FileStoreFactory;
import quickfix.ScreenLogFactory;
import quickfix.Session;
import quickfix.SessionID;
import quickfix.SessionNotFound;
import quickfix.SessionSettings;
import quickfix.SocketInitiator;
import quickfix.field.ClOrdID;
import quickfix.field.OrdType;
import quickfix.field.OrderQty;
import quickfix.field.Price;
import quickfix.field.Side;
import quickfix.field.Symbol;
import quickfix.field.TransactTime;
import quickfix.fix44.NewOrderSingle;
public class SenderApp {
public static void main(String[] args) throws ConfigError, InterruptedException, SessionNotFound {
SessionSettings settings = new SessionSettings("sender.cfg");
Application myApp = new FIXSender();
FileStoreFactory fileStoreFactory = new FileStoreFactory(settings);
ScreenLogFactory screenLogFactory = new ScreenLogFactory(settings);
DefaultMessageFactory msgFactory = new DefaultMessageFactory();
SocketInitiator initiator = new SocketInitiator(myApp, fileStoreFactory, settings,
screenLogFactory, msgFactory);
initiator.start();
Thread.sleep(3000);
// matching values from sender.cfg
SessionID sessionID = new SessionID("FIX.4.4", "CLIENT1", "FixServer");
NewOrderSingle order = new NewOrderSingle(new ClOrdID("DLF"), new Side(Side.BUY),
new TransactTime(new Date()), new OrdType(OrdType.LIMIT));
order.set(new OrderQty(45.00));
order.set(new Price(25.40));
order.set(new Symbol("BHP"));
Session.sendToTarget(order, sessionID);
Thread.sleep(60000);
initiator.stop();
}
}
Step 8: Run the ReceiverApp.
log4j:WARN No appenders could be found for logger (quickfix.SessionSchedule). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. <20140731-01:59:36, FIX.4.4:FixServer->CLIENT1, event> (Session FIX.4.4:FixServer->CLIENT1 schedule is daily, 00:00:00-UTC - 00:00:00-UTC) <20140731-01:59:36, FIX.4.4:FixServer->CLIENT1, event> (Created session: FIX.4.4:FixServer->CLIENT1) Receiver onCreate.. FIX.4.4:FixServer->CLIENT1 press <enter> to quit
Step 9: Run the SenderApp.
log4j:WARN No appenders could be found for logger (quickfix.SessionSchedule). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. <20140731-01:59:44, FIX.4.4:CLIENT1->FixServer, event> (Session FIX.4.4:CLIENT1->FixServer schedule is daily, 00:00:00-UTC - 00:00:00-UTC) <20140731-01:59:44, FIX.4.4:CLIENT1->FixServer, event> (Created session: FIX.4.4:CLIENT1->FixServer) <20140731-01:59:45, FIX.4.4:CLIENT1->FixServer, outgoing> (8=FIX.4.4 9=72 35=A 34=52 49=CLIENT1 52=20140731-01:59:45.635 56=FixServer 98=0 108=30 10=203 ) <20140731-01:59:45, FIX.4.4:CLIENT1->FixServer, event> (Initiated logon request) <20140731-01:59:45, FIX.4.4:CLIENT1->FixServer, incoming> (8=FIX.4.4 9=72 35=A 34=41 49=FixServer 52=20140731-01:59:45.672 56=CLIENT1 98=0 108=30 10=202 ) <20140731-01:59:45, FIX.4.4:CLIENT1->FixServer, event> (Received logon) Sender toApp: 8=FIX.4.4 9=123 35=D 34=53 49=CLIENT1 52=20140731-01:59:47.671 56=FixServer 11=DLF 38=45 40=2 44=25.4 54=1 55=BHP 60=20140731-01:59:47.669 10=238 <20140731-01:59:47, FIX.4.4:CLIENT1->FixServer, outgoing> (8=FIX.4.4 9=123 35=D 34=53 49=CLIENT1 52=20140731-01:59:47.671 56=FixServer 11=DLF 38=45 40=2 44=25.4 54=1 55=BHP 60=20140731-01:59:47.669 10=238 ) <20140731-02:00:15, FIX.4.4:CLIENT1->FixServer, incoming> (8=FIX.4.4 9=60 35=0 34=42 49=FixServer 52=20140731-02:00:15.918 56=CLIENT1 10=145 ) <20140731-02:00:18, FIX.4.4:CLIENT1->FixServer, outgoing> (8=FIX.4.4 9=60 35=0 34=54 49=CLIENT1 52=20140731-02:00:18.604 56=FixServer 10=143 ) <20140731-02:00:46, FIX.4.4:CLIENT1->FixServer, incoming> (8=FIX.4.4 9=60 35=0 34=43 49=FixServer 52=20140731-02:00:46.916 56=CLIENT1 10=148 ) <20140731-02:00:48, FIX.4.4:CLIENT1->FixServer, event> (Initiated logout request) <20140731-02:00:48, FIX.4.4:CLIENT1->FixServer, outgoing> (8=FIX.4.4 9=60 35=5 34=55 49=CLIENT1 52=20140731-02:00:48.603 56=FixServer 10=151 ) <20140731-02:00:48, FIX.4.4:CLIENT1->FixServer, incoming> (8=FIX.4.4 9=60 35=5 34=44 49=FixServer 52=20140731-02:00:48.607 56=CLIENT1 10=153 ) <20140731-02:00:48, FIX.4.4:CLIENT1->FixServer, error> (quickfix.SessionException Logon state is not valid for message (MsgType=5)) <20140731-02:00:48, FIX.4.4:CLIENT1->FixServer, event> (Already disconnected: Verifying message failed: quickfix.SessionException: Logon state is not valid for message (MsgType=5))
Step 10: The receiver or acceptor logs grow further to
<20140731-01:59:45, FIX.4.4:FixServer->CLIENT1, incoming> (8=FIX.4.4 9=72 35=A 34=52 49=CLIENT1 52=20140731-01:59:45.635 56=FixServer 98=0 108=30 10=203 ) <20140731-01:59:45, FIX.4.4:FixServer->CLIENT1, event> (Accepting session FIX.4.4:FixServer->CLIENT1 from /127.0.0.1:60832) <20140731-01:59:45, FIX.4.4:FixServer->CLIENT1, event> (Acceptor heartbeat set to 30 seconds) <20140731-01:59:45, FIX.4.4:FixServer->CLIENT1, event> (Received logon) <20140731-01:59:45, FIX.4.4:FixServer->CLIENT1, event> (Responding to Logon request) <20140731-01:59:45, FIX.4.4:FixServer->CLIENT1, outgoing> (8=FIX.4.4 9=72 35=A 34=41 49=FixServer 52=20140731-01:59:45.672 56=CLIENT1 98=0 108=30 10=202 ) Receiver onLogon..FIX.4.4:FixServer->CLIENT1 <20140731-01:59:47, FIX.4.4:FixServer->CLIENT1, incoming> (8=FIX.4.4 9=123 35=D 34=53 49=CLIENT1 52=20140731-01:59:47.671 56=FixServer 11=DLF 38=45 40=2 44=25.4 54=1 55=BHP 60=20140731-01:59:47.669 10=238 ) Receiver fromApp.. 8=FIX.4.4 9=123 35=D 34=53 49=CLIENT1 52=20140731-01:59:47.671 56=FixServer 11=DLF 38=45 40=2 44=25.4 54=1 55=BHP 60=20140731-01:59:47.669 10=238 Receiver onMessage.. 8=FIX.4.4 9=123 35=D 34=53 49=CLIENT1 52=20140731-01:59:47.671 56=FixServer 11=DLF 38=45 40=2 44=25.4 54=1 55=BHP 60=20140731-01:59:47.669 10=238 <20140731-02:00:15, FIX.4.4:FixServer->CLIENT1, outgoing> (8=FIX.4.4 9=60 35=0 34=42 49=FixServer 52=20140731-02:00:15.918 56=CLIENT1 10=145 ) <20140731-02:00:18, FIX.4.4:FixServer->CLIENT1, incoming> (8=FIX.4.4 9=60 35=0 34=54 49=CLIENT1 52=20140731-02:00:18.604 56=FixServer 10=143 ) <20140731-02:00:46, FIX.4.4:FixServer->CLIENT1, outgoing> (8=FIX.4.4 9=60 35=0 34=43 49=FixServer 52=20140731-02:00:46.916 56=CLIENT1 10=148 ) <20140731-02:00:48, FIX.4.4:FixServer->CLIENT1, incoming> (8=FIX.4.4 9=60 35=5 34=55 49=CLIENT1 52=20140731-02:00:48.603 56=FixServer 10=151 ) <20140731-02:00:48, FIX.4.4:FixServer->CLIENT1, event> (Received logout request) <20140731-02:00:48, FIX.4.4:FixServer->CLIENT1, outgoing> (8=FIX.4.4 9=60 35=5 34=44 49=FixServer 52=20140731-02:00:48.607 56=CLIENT1 10=153 ) <20140731-02:00:48, FIX.4.4:FixServer->CLIENT1, event> (Sent logout response)
posted by Unknown at
7/31/2014 02:22:00 PM
|
0 Comments
![]()
![]()